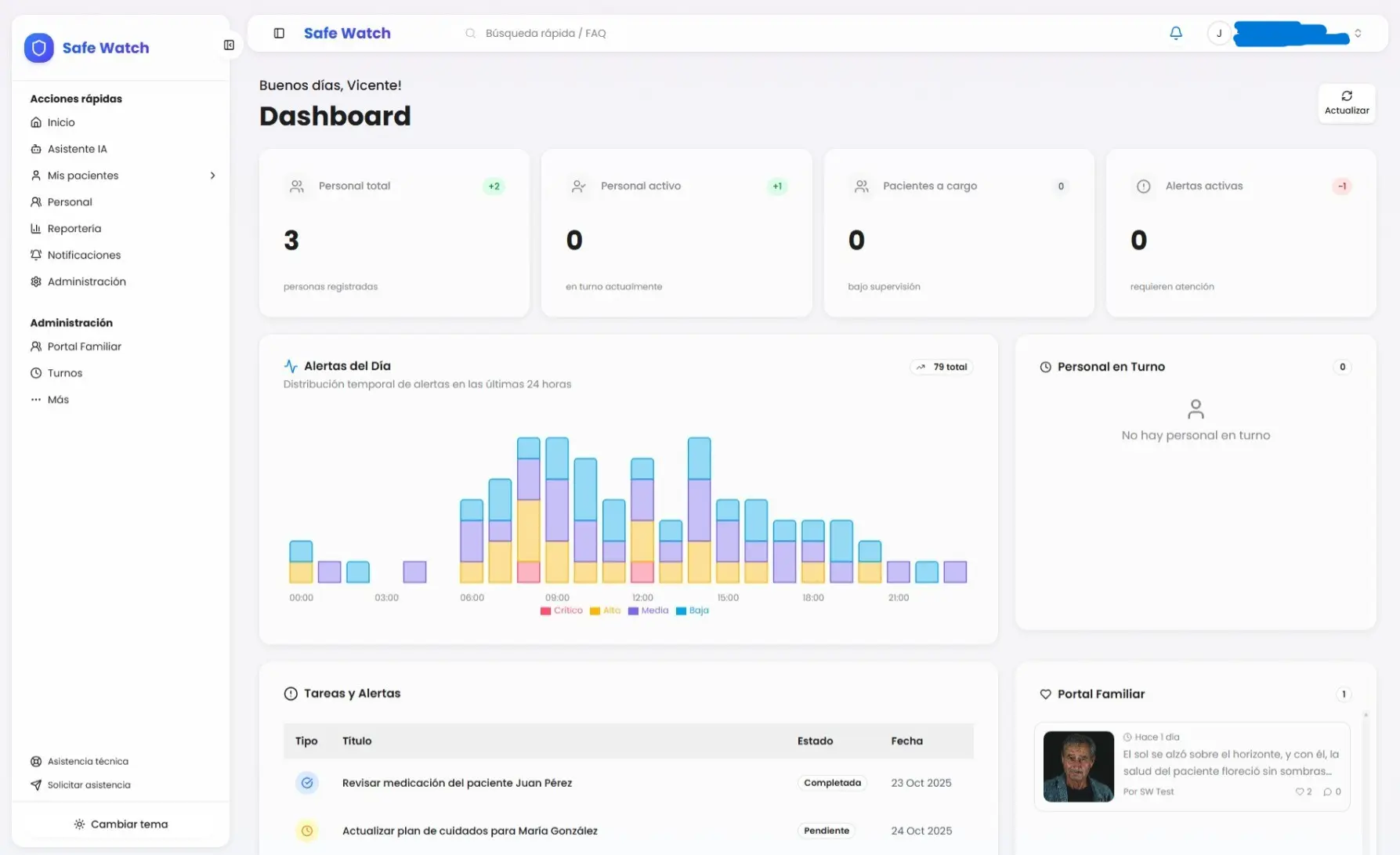
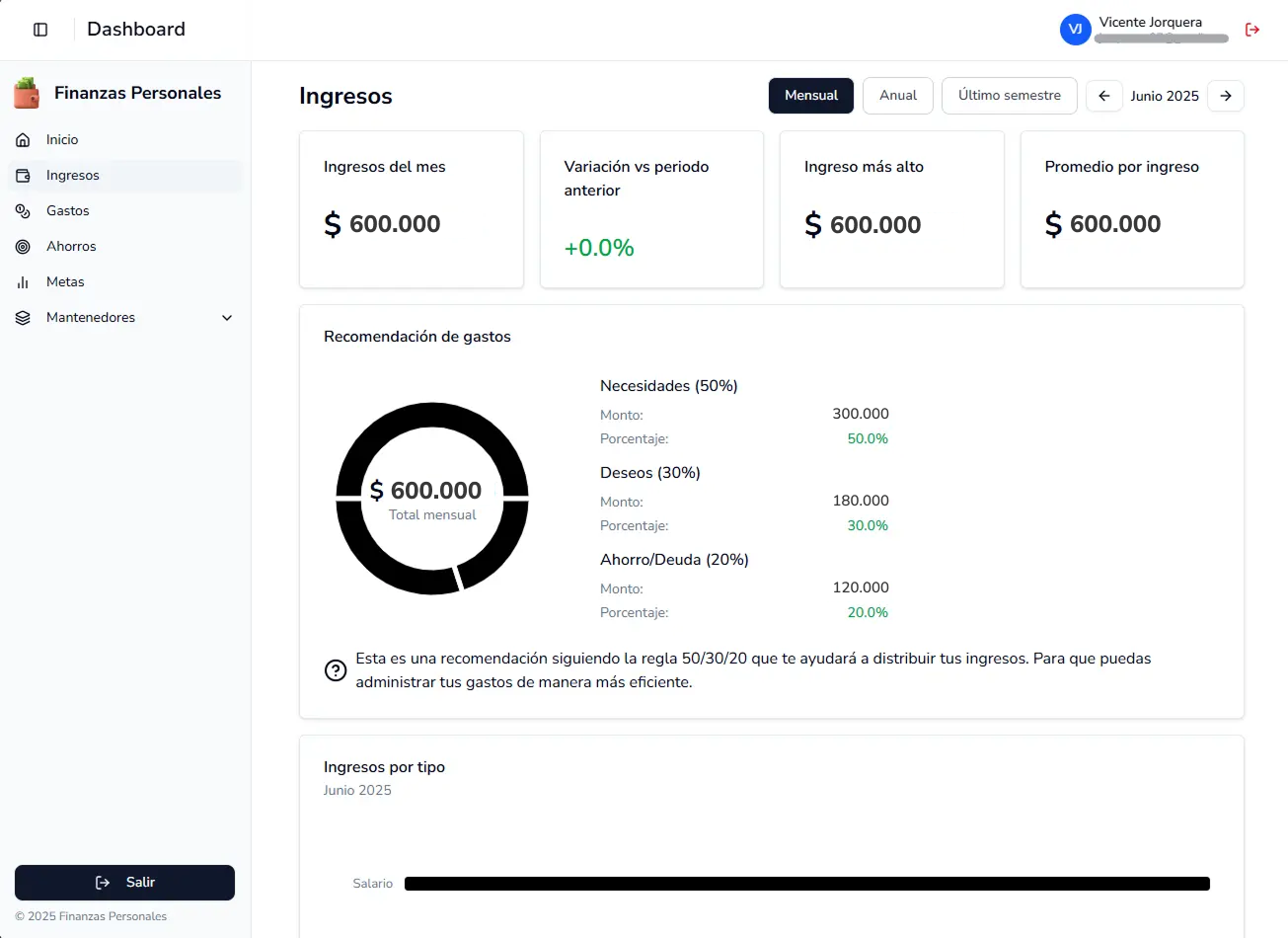
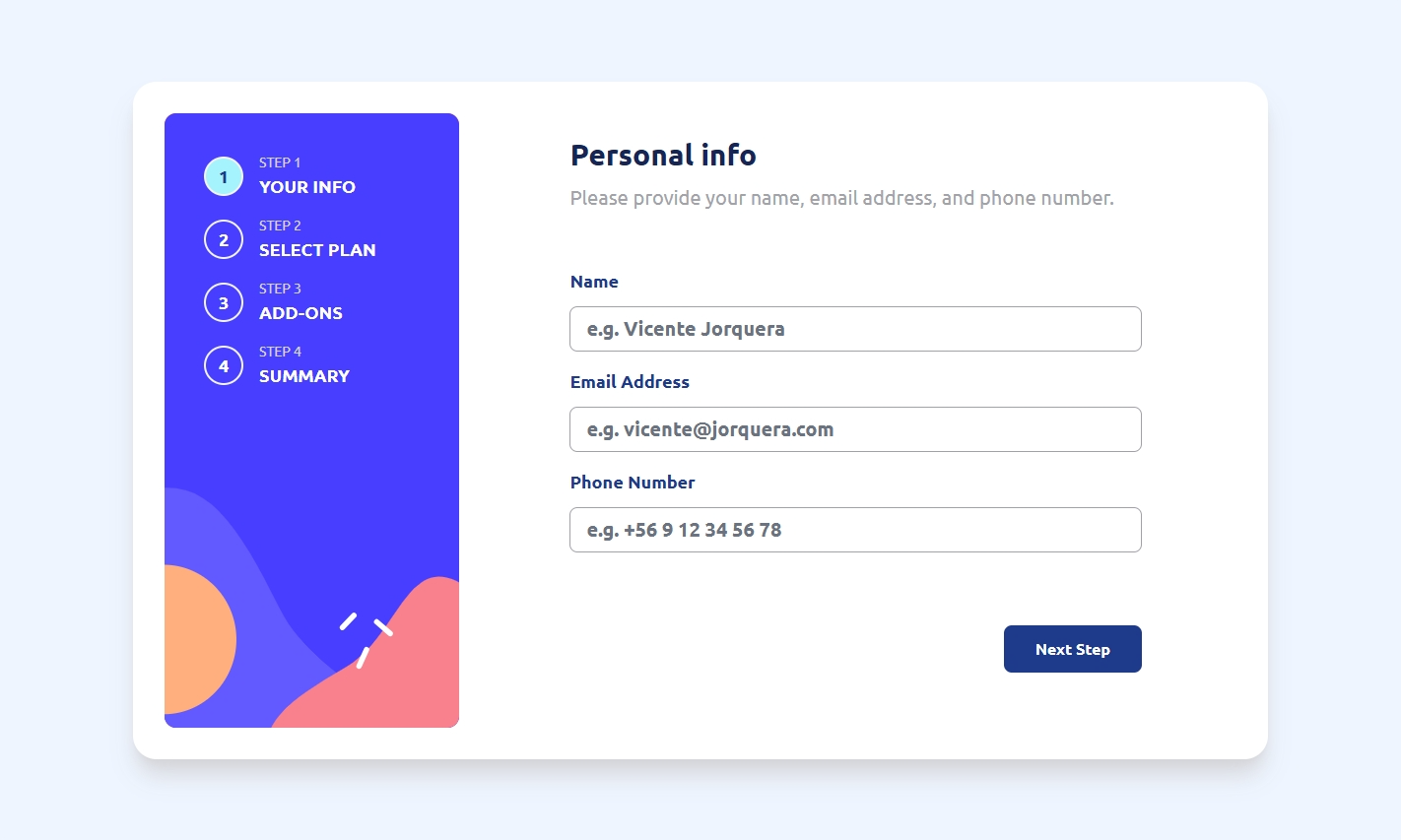
Hola, soy Vicente Jorquera 👋
¡Hola! Soy Arquitecto de Software e Ingeniero en Informática, enfocado en transformar desafíos complejos en sistemas robustos. Recientemente culminé mi Ingeniería en Informática, validando mi trayectoria con una tesis destacada por su visión integral y rigor técnico. Mi especialidad es mover el límite de lo posible mediante la nube (Azure/AWS), el IoT y la IA. Creo firmemente en la optimización constante, tanto en el código como en la vida, donde disfruto del aprendizaje continuo y de las caminatas con mis mascotas.